1.2. The History of AI: From Statistics to Artificial Intelligence
Summary: Machine learning did not emerge overnight—it evolved through a long history rooted in mathematics, statistics, and early artificial intelligence research.
Look at these paintings of what people in the 1900 thought the year 2000 would look like.





It is interesting to see that people of the 1900s wanted automated tools to help with their daily chores such as cleaning, washing clothes, grooming, and more. Now, in the 21st century, we are slowly witnessing all of these come into fruition. We now have machines that can converse like humans, help with manual work such as sorting things, and even help scientists formulate hypothesis from existing body of research.
We have come a long way indeed. And there is still a long way to go from here. In this lesson, we will take a step back in time and explore how AI grew the way it is today. It is necessary to understand where it came from for us to know where we should go next. Let us start with its roots – statistics and mathematics!
The Foundations in Statistics (1800s–1940s)
Machine learning, and eventually AI, started from statistical methods like linear regression and the Bayes’ Theorem, to name a few. These concepts helped laid the groundwork for data-driven modeling long before computers even existed.
In 1805, Isaac Newton was credited for inventing what we now know today as linear regression analysis. He did it when he worked with equinoxes in 1700s and wrote down the first of the two normal equations of the ordinary least squares method (OLS). At the same time, Adrien-Marie Legendre developed the least squares method which found many applications in linear regression, signal processing, and curve fitting. The least squares method was popularized when Carl Friedrich Gauss used it for predicting planetary movements in 1809, while Adolphe Quetelet made the method well-known in the social sciences.
Fast forward to 1812, Thomas Bayes developed a theorem (named Bayes’ theorem) that provides a method for updating probabilities of an event happening based on new or additional evidence. Bayes’ work was published in 1763 as An Essay Towards Solving a Problem in the Doctrine of Chances. Independently of Bayes, Pierre-Simon Laplace also used conditional probability to describe how to update a belief (posterior probability) based on prior knowledge and new evidence. In 1774, he reproduced and extended Bayes’ results (without knowing about Bayes’ earlier work) and later published in his 1812 book Théorie analytique des probabilités.

During the late 1800s, Karl Pearson developed the Pearson Correlation Coefficient (PCC) from a related idea introduced by Francis Galton. PCC measures the linear correlation between two sets of data. It is the covariance of two variables divided by the product of their standard deviations. PCC normalizes the value so the result would always fall between -1 and +1.
In the early 1900s, classical statistical inference began to grow. Statistical inference uses data analysis to infer properties on an underlying probability distribution. For example, it infers properties of a population by testing hypotheses and deriving estimates. Figures like Ronal Fisher, Jerzy Neyman, and Egon Pearson advanced the field and introduced concepts like p-values and confidence intervals. These tools influenced model validation, hypothesis-driven research, and the design of experiments.
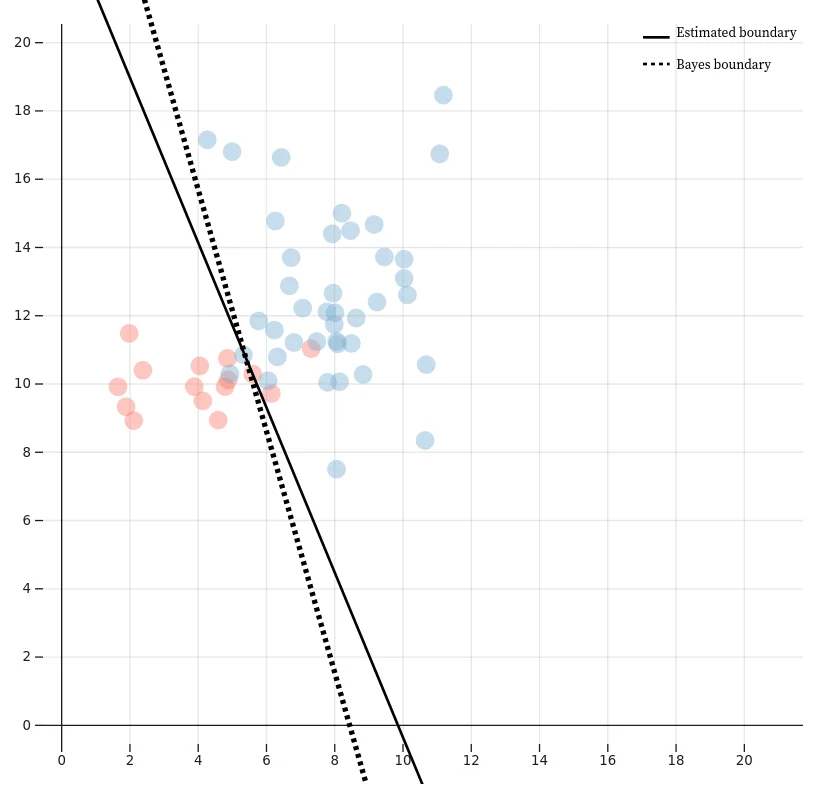
Finally, in 1936, Sir Ronald Fisher developed Linear Discriminant Analysis (LDA). LDA became an early method for classification, which eventually turned into a precursor for modern supervised learning techniques.
The Birth of Computing and Symbolic AI (1940s–1960s)
The rise of digital computing enabled researchers to simulate reasoning processes, leading to early symbolic AI systems focused on logic and rules.
In 1943, Warren S. McCulloch and Walter Pitts published “A Logical Calculus of the Ideas Immanent in Nervous Activity” in the Bulletin of Mathematical Biophysics. In this paper, McCulloch and Pitts tried to understand how the brain could produce highly complex patterns by using many basic cells that are connected. They simplified this connection and made a model of a neuron in their paper. This model made an important contribution to the development of artificial neural networks, which then paved the way for modern artificial intelligence. The McCulloch-Pitt model of the neuron is considered to be the first neural network recorded.

In 1945, John Von Neumann described an architecture for an electronic digital computer with parts consisting of a processing unit and processor registers. Also known as the Princeton Architecture, the Von Neumann Architecture became the blueprint for modern digital computers.
Five years later in 1950, Alan Turing proposed a test for machine intelligence known today as the Turing Test. Originally called the Imitation Game, the Turing Test tests a machine’s ability to exhibit intelligent behavior like a human. In this test, a human evaluator judges a text transcript of a natural language conversation between a human and a machine. The evaluator will try to identify who the machine is from the conversation. The machine passes the test if the evaluator cannot reliably tell them apart.
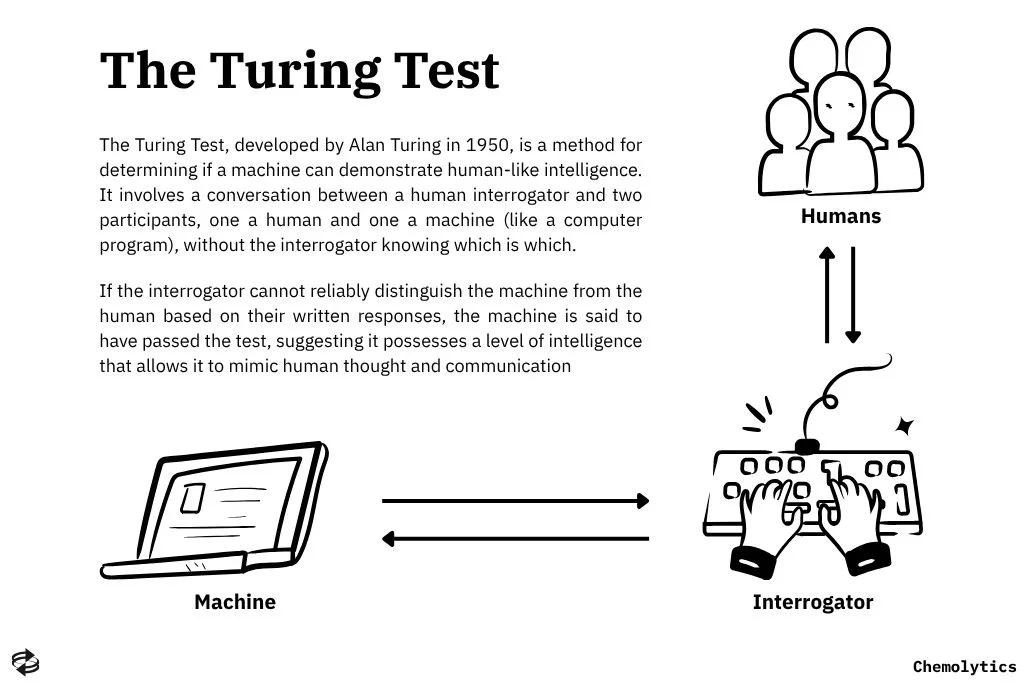
Although the Turing Test is not a reliable test of machine intelligence anymore, it served as a foundational concept that shaped early thinking around artificial intelligence. It framed intelligence in terms of observable behavior rather than internal processes, influencing decades of AI research focused on mimicking human responses. While modern AI systems often exceed the test’s original scope, especially in language generation, the Turing Test remains a historical milestone in the philosophical and practical exploration of machine cognition.
Two years after Turing’s death in 1954, theDartmouth Conference was held. John McCarthy, Marvin Minsky, Nathaniel Rochester, and Claude Shannon organized a summer workshop to clarify and develop ideas about thinking machines. It is in this conference that the term “Artificial Intelligence” was coined. This marked the birth of AI as a formal field of study, aiming to find how machines use language, form abstractions and concepts, solve kinds of problems now reserved for humans, and improve themselves. In 1958, McCarthy then created the LISP Language which enabled symbolic computation.
One year after (1959), Arthur Samuel’s Checkers Program pioneered the demonstration of machine learning using rote learning and heuristics. The program learned by remembering past game positions and their evaluated values, eventually improving its play over time. The Checker’s Program also employed a method known as learning by generalization. It modifies a value function based on game experience, which resembled later temporal-difference learning techniques.

The Rise and Fall of Expert Systems (1970s–1980s)
In 1972, MYCIN was developed as a rule-based expert system for medical diagnosis. It pioneered the use of knowledgebases and inference engines. MYCIN used AI to identify bacteria causing severe infections such as bacteremia and meningitis. It also recommended antibiotics with the dosage adjusted based on the patient. Developed for over five to six years, Edward Shortliffe wrote MYCIN in LISP as his doctoral dissertation at Stanford University.
On the other hand, PROLOG was also developed at the same time. It is a logic programming language created in 1972 for symbolic AI and expert systems. It used a declarative language, meaning you need to define the rules and facts, while the system will infer solutions. Prolog is particularly well-suited for tasks like database search, natural language processing, and building expert systems.
The surge in AI research led to the Knowledge Engineering Boom. The Knowledge Engineering Boom refers to the increased focus in AI research on building systems that can reason and solve problems by explicitly representing domain expertise as rules and knowledge. Knowledge engineering aims to capture and encode human expertise in a way that a computer can understand and use to make decisions, solve problems, or provide explanations.
The AI Winter (Late 1980s-Late 1990s)
With all this progress, expert systems dominated the earliest efforts to achieve machine intelligence. However, they eventually failed due to the computational limits of the time. This era is known as the AI Winter which happened during the late 80s to late 90s.
One of the reasons why progress towards AI halted was because funding and interest declined as expert systems proved to be brittle. This means that these systems struggled with ambiguity or novel situations. In addition, as different domains of study grew and expanded, expert systems failed to keep up, limiting their scalability. Lastly, the cost of maintaining, updating, and debugging them grew larger than the returns. As expectations outpaced results, both government and private investment in AI research significantly dropped, stalling the field’s momentum for nearly a decade.
Roger Schank and Marvin Minsky, two leading AI researchers during the AI winter, warned the business community that enthusiasm for AI spiraled out of control and disappointment would certainly follow. They likened AI winter to a nuclear winter, where it begins with pessimism towards the AI community, followed by pessimism in the press, then severe cutback in funding, and then ultimately ending serious research in the field. Soon enough, the billion-dollar AI industry collapsed, and interest almost dropped to zero.
- Late 1980s: Disillusionment grows with expert systems as they prove too rigid, expensive to maintain, and unable to handle real-world complexity.
- 1987–1989: Collapse of the Lisp machine market (hardware built for AI) signals a broader industry retreat from symbolic AI.
- Early 1990s: Funding cuts hit major AI programs in the U.S., U.K., and Japan (e.g., Japan’s Fifth Generation Project ends in disappointment).
- Mid-1990s: AI research becomes less prominent in mainstream computer science; focus shifts to more practical fields like database systems and software engineering.
Shift Towards Statistical Learning (1990s)
A pivot occurred when researchers shifted their perspective towards statistical models and probabilistic thinking. AI circled back to its roots, borrowing ideas from classical inferential statistics and mathematics, and even paved a way to the rise of support vector machines, decision trees, and ensemble methods.
The development of support vector machines in 1995 revived the interest on machine intelligence. Classifying data is a common task in machine learning and SVM proved to be successful in classifying new and unseen data. SVM works by finding the optimal hyperplane that best separates different classes in the data. It maximizes the margin between data points of different categories, making it robust to overfitting. With the use of kernel functions, SVMs can also handle complex, high-dimensional datasets, making them widely applicable in fields like bioinformatics, image recognition, and text classification.
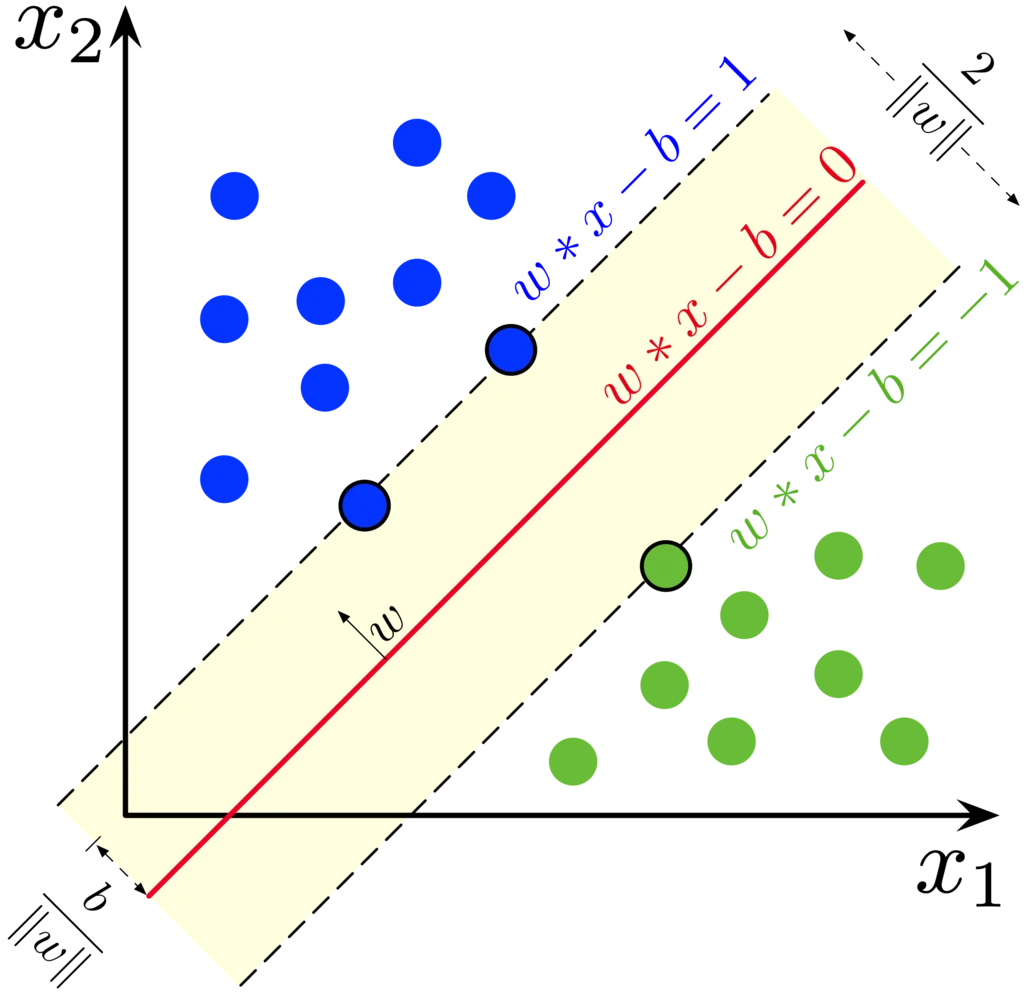
SVMs offered strong theoretical guarantees and high performance in classification tasks, especially in high-dimensional spaces. The success of this algorithm showed that machine learning could outperform rule-based systems, shifting the attention towards data-driven AI.
Techniques like Random Forests and AdaBoost also gained attention by improving the accuracy of a prediction by combining multiple models. Ensemble methods like bagging and boosting combined models to reduce variance and improve overall performance compared to using a single model. Combining weaker models into a strong model significantly improved the accuracy of the algorithm and helped overcame the instability and variance issues seen in single models. This made machine learning more reliable and competitive across different domains like finance, medicine, and marketing.
Probabilistic graphical models (PGMs) like Bayesian networks and Hidden Markov Models also gained traction for representing uncertainty and complex dependencies in data. PGMs combined probability theory and graph theory to provide a flexible framework for modeling large collection of random variables with complex interactions. By modeling uncertainty and dependencies explicitly, PGMs brought powerful tools for reasoning under uncertainty, something symbolic AI struggled with.
Together, these innovations made AI more robust, generalizable, and applicable to real-world data—reigniting academic and industrial interest after the failures of expert systems.
The Emergence of Modern Machine Learning (2000s–2015)
As humans generate more data and computational power improves exponentially, machine learning matured into a mature field, powered by neural networks, optimization algorithms, and large-scale datasets.
In 2006, interest in deep learning was revived and attention to neural networks returned. Geoffrey Hinton and his colleagues introduced deep belief networks (DBNs), reigniting interest in neural networks after decades of stagnation. Their work showed an effective way to train DBNs using a greedy layer-wise pre-training strategy, overcoming the challenges of vanishing or exploding gradients in traditional deep networks. The introduction of DBNs reignited the interest in deep learning and paved the way for the widespread adoption of deep neural networks.
In 2009, Fei-Fei Li launched ImageNet, a massive, labeled dataset that became the benchmark for computer vision and fueled the interest in deep learning. The main purpose of ImageNet is to serve as a large visual database for use in visual object recognition research. It contains more than 14 million images annotated by hand, indicating what objects are in the picture. The database of annotations of third-party image URLs is freely available directly from ImageNet, though the actual images are not owned by ImageNet.

Optimization algorithms also began to improve significantly. The introduction of Adam in 2014 (a method that combines the advantages of both AdaGrad and RMSProp) allowed for faster and more reliable convergence during training. Alongside this, refinements in backpropagation techniques and weight initialization helped address issues like vanishing or exploding gradients. These advances made it possible to train deeper neural networks more efficiently and stably, accelerating progress in deep learning applications.
Another important factor in the development of modern machine learning includes the improvements in computer architecture, including advanced GPUs, distributed computing, and cloud platforms. These developments enabled training of large-scale models on massive datasets (billions of datapoints). This infrastructure has made it possible to process and analyze very large amounts of data, supporting advanced analytics and machine learning applications.
Adoption of machine learning and developments in AI was popularized in the media when Thomas Davenport and DJ Patil published an article in the Harvard Business Review entitled: Data Scientist: The Sexiest Job of the 21st Century. This article was so influential it led to a massive army of people jumping into data science as a job opportunity. Aside from that, the article also validated the central role of data science in modern machine learning and AI. It also helped to elevate the profile of data science and its practitioners, influencing many organizations to seek data science and machine learning talents.

Deep Learning and the AI Renaissance (2012–Present)
Led by breakthroughs in computer vision, deep neural networks, and language models, AI sustained global interest and reshaped how models learn from data. In an article published in The Economist, data became the most valuable resource than oil.
In 2017, the Transformer architecture revolutionized natural language processing by replacing recurrence and convolutions with a simpler, attention-only mechanism. This made models faster to train and more parallelizable. Transformers outperformed previous state-of-the-art methods in machine translation tasks and laid the groundwork for powerful models like BERT and GPT. Their success also showed strong generalization across various NLP tasks, setting a new standard for sequence modeling.
From 2018 onwards, artificial intelligence entered a new era marked by the rise of foundation models and large language models (LLMs). Models like BERT, GPT-3, Claude, and PalM were trained on massive datasets, enabling them to understand and perform a wide range of tasks, from writing content to giving codes. This generalization ability made LLMs highly adaptable, shifting AI from narrow applications to more versatile, human-like performance.

At the same time, generative models saw rapid advancement. Techniques such as GANs (Generative Adversarial Networks), VAEs (Variational Autoencoders), and diffusion models allowed AI to produce realistic images, audio, video, and text. Tools like DALL·E, Midjourney, and Stable Diffusion emerged from this wave, transforming fields like art, design, entertainment, and education.
Together, these innovations established a new frontier in AI, where models not only interpret data but also create it, setting the stage for broader human-AI collaboration.
Integration with Scientific Research
Today, machine learning and AI are not just limited to finance, marketing, and business, but they also found a way to penetrate the natural and physical science. Scientists use them to accelerate discovery and automate pattern recognition in complex systems.
For instance, Dr Kristin Persson of Lawrence Berkeley National Laboratory founded the Materials Project, an initiative offering an open-access database of material properties. The goal of this project is to accelerate the development of technology by predicting how new materials, both real and hypothetical, can be used. They use supercomputers at Berkeley to run calculations using Density Functional Theory.
In 2018, Demis Hassabis and John M. Jumper (both from DeepMind) developed AlphaFold, an AI program that predicts protein structure from its amino acid components. In 2020, they updated the program to AlphaFold2 which achieved a level of accuracy much higher than any other entries in the Critical Assessment of Structure Prediction (CASP) competition. The results of AlphaFold2 were so “astounding” and “transformational” that Hassabis and Jumper shared the 2024 Nobel Prize in Chemistry for protein structure prediction, along with David Baker for computational protein design.

In recent years, a growing ecosystem of tools and libraries has emerged to support the application of machine learning and AI in chemistry. Beyond AlphaFold, chemists now use platforms like DeepChem, an open-source library tailored for cheminformatics and molecular machine learning, and Chemprop, which enables molecular property prediction using message passing neural networks. Tools like ASE (Atomic Simulation Environment) and SchNetPack integrate ML with quantum chemistry workflows, allowing simulations and model training on molecular structures and reactions. Libraries such as RDKit are widely used for molecular representation, descriptor calculation, and structure manipulation. These tools empower chemists to automate analysis, accelerate discovery, and build predictive models that bridge traditional chemistry with modern data science.
Just this year, Google Researchers introduced AI Co-Scientist, a multi-agent system built with Gemini 2.0 as a virtual scientific collaborator to help scientists generate novel hypotheses and research proposals. Unlike single-output AI tools that just summarize papers or answer questions, this system mimics how scientists actually work: generating ideas, debating them, refining them, and proposing experiments—iteratively and autonomously.
Closing Reflection
Machine learning is not a replacement for science—it is an evolution of it, built on the foundations of statistics, logic, computation, and empirical discovery. From early symbolic systems and expert rules to today’s large-scale neural networks and generative models, the development of AI reflects a gradual shift toward data-driven reasoning. In scientific fields like chemistry, physics, and biology, ML is becoming a powerful collaborator by accelerating discovery, modeling complex systems, and uncovering patterns that traditional methods struggle to detect. As tools continue to evolve, the synergy between machine learning and science will not diminish the role of human inquiry. Rather, it will enhance it, enabling researchers to ask deeper questions and explore previously unreachable frontiers.
